In the last two sections, we’ve covered the overall approach to the problem of unit testing notebooks as well as a notebook structure that enables source data from different databases, but how does the data get to those databases?
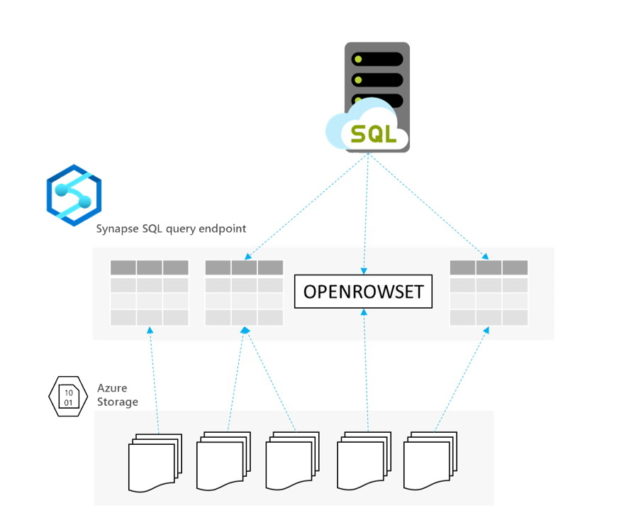
As I explained in the first post, we are using the medallion architecture. On normal runs, the query in the example would source its data from Silver zone delta tables, but during test runs it sources from a database called “unit_test_db”.
We need to create some sort of process that takes seed data and populates the tables in this database, and this is where databricks-connect and a Python project come into play.
Continue reading →