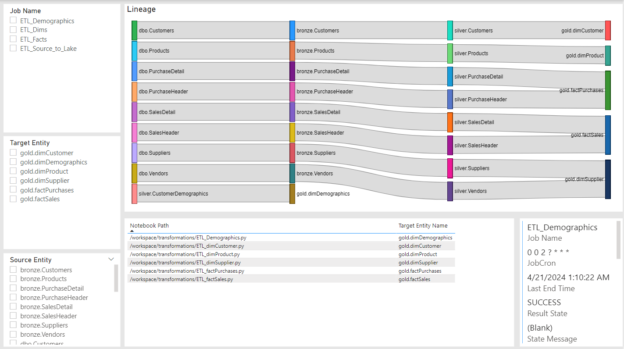
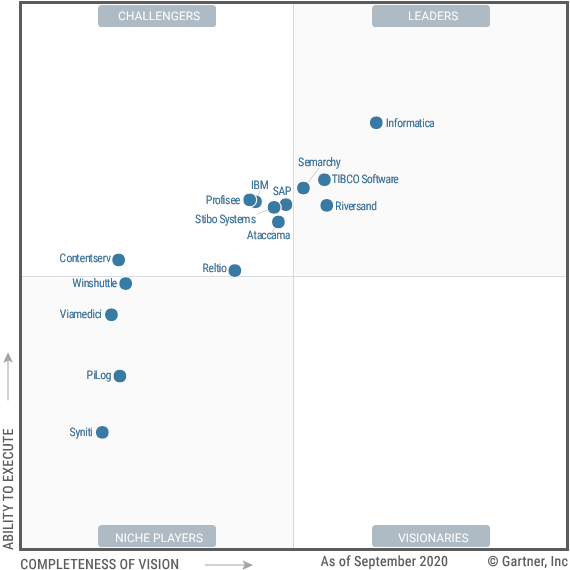
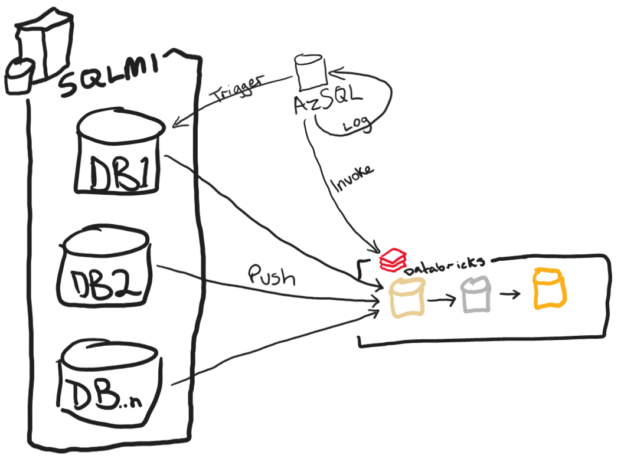
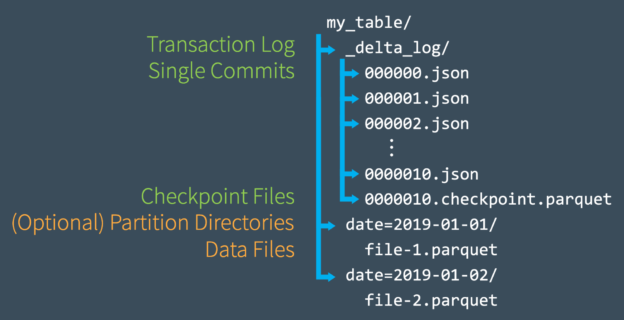
When I first relocated to Colorado I worked for a global company in a local role. During my almost 5 year stay there, I grew into a global role with oversight over all things data coming from and going into their ERP system. I helped with 6 regional implementations into a global JD Edwards system and worked very closely with the brilliant Jiri Svoboda. At the time he held the position of Global Master Data Manager and I head the position of Global ERP Data Architect Manager. We were at the beginning of the company’s digital transformation and were tasked to take the somewhat manual Data Migration and Master Data Management (MDM) processes and modernize them. We shopped around various Gartner leaders in data management solutions. We had demos and POCs from both IBM, Informatica, and some boutique data management vendors. We landed on Informatica because they were, and still are, lightyears ahead of others in the world of MDM. What we learned was that Master Data Management, Data Governance, and analytics on data quality are super important, but tools will only get you so far. In this blog post, I’ll share my perspective on what worked for us and what I would do differently if I had to do it again.
Continue reading →