

I was privileged enough to be able to attend the Microsoft AI Tour in Chicago a couple of weeks ago, so I decided to take the slides which I presented to my internal team about my takeaways and write a blog post about them.
The one-day conference brought together thought leaders, technologists, and innovators to explore the evolving landscape of artificial intelligence, specifically in terms of Agentic Systems. From keynote sessions to deep technical dives, the event showcased how they are reshaping industries and redefining enterprise capabilities.
The day started with what would be the most interesting of all the sessions I attended – ‘Industrial AI in Action’. The session provided real-world examples of agentic systems in use for companies which were considered industrious or delt in the manufacturing space. There’s been a lack of good examples of AI/ML, Fabric, or Databricks use cases as they pertain to the construction sector, which I currently work in, at any conference I’ve attended. This session was as close as it could get. Companies like Harting, Eneco, Kuka, and Rolls Royce demonstrated how AI can streamline operations, enhance automation, and improve accuracy. Harting’s internal tools accelerated product configuration, while Eneco’s chat agents reduced noise and improved automation. Kuka integrated AI into their IDE for industrial automation, and Rolls Royce leveraged Azure ML for inspection automation. It ended with a lightning talk with Brandon Hootman, VP of Data and AI at Caterpillar. Clear communication and the simplification of the message of “What AI is” were core to Caterpillar’s success in their agentic journey. He encouraged the audience to “tear down all ‘AI/ML’ systems” and to rethink what brings actual business value before developing anything new with agents. That there should be a very short evaluation period to check for adoption and value before an agent is kept or scrapped. What I found most interesting about this session is the culture of data governance that has been created at Caterpillar. They no longer look at it as an initiative and “data governance” has become a bad word there. They instead ingrain it within all their processes and live a culture of data governance. I’d be curious to see what this looks like in practice and how effective removing the red tape can be.

The keynote was compelling as well. Titled ‘Becoming Frontier’, it emphasized the democratization of intelligence. The concept of Agentic-Operations was introduced in three progressive phases: Assistants, Collaborators, and Orchestrators.
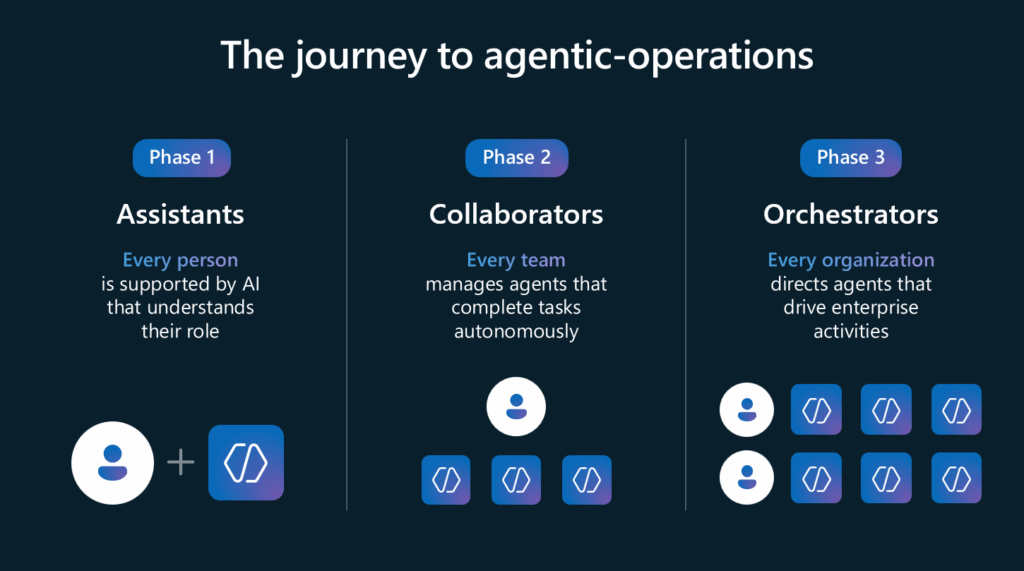
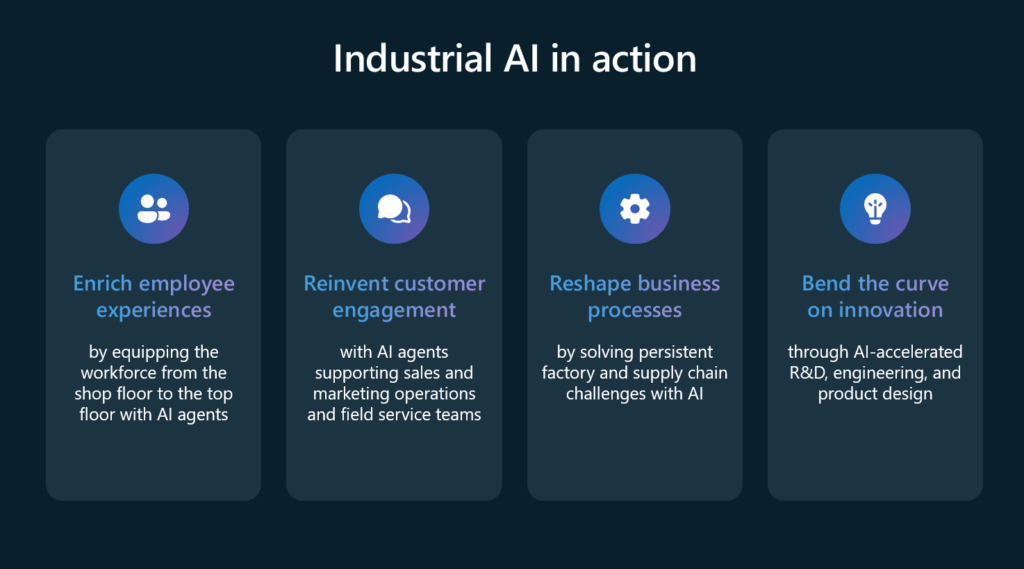
These phases illustrate how AI can evolve from supporting individuals to orchestrating enterprise-wide activities. The keynote also outlined four strategic purposes for AI: enriching employee experiences, reinventing customer engagement, reshaping business processes, and accelerating innovation. Technologies like Model Context Protocols (MCP) and GitHub Copilot were highlighted as enablers of these transformations.
I next attended a session which was put on by a company called Elastic entitled “Using AI to manage scale in observability”. They showcased how their tools can ingest logs from various systems and integrate with platforms like ServiceNow. The rapid pace of development has outstripped traditional observability platforms, creating delays in mean time to resolution (MTTR). This was one of those sales pitch type sessions, so I didn’t take too much from it besides the curiosity of what we are doing with our Kubernetes and Spark logs, if anything. Maybe there’s something I could consider exploring there, but I don’t see the value in it for my work at the moment since we aren’t a hardcore Kubernetes shop.
The “Enable agentic AI apps with a unified data estate in Microsoft Fabric” session served as an introductory overview of the Fabric landscape, at best, with a brief mention of agents at the end. It wasn’t the best presentation, so I left it early. Come to think of it, data engineering with tools like Fabric was kind of overlooked during the entire day. Data quality and a good foundation of data and knowledge took a backseat to justifying standing up agents as fast as possible.
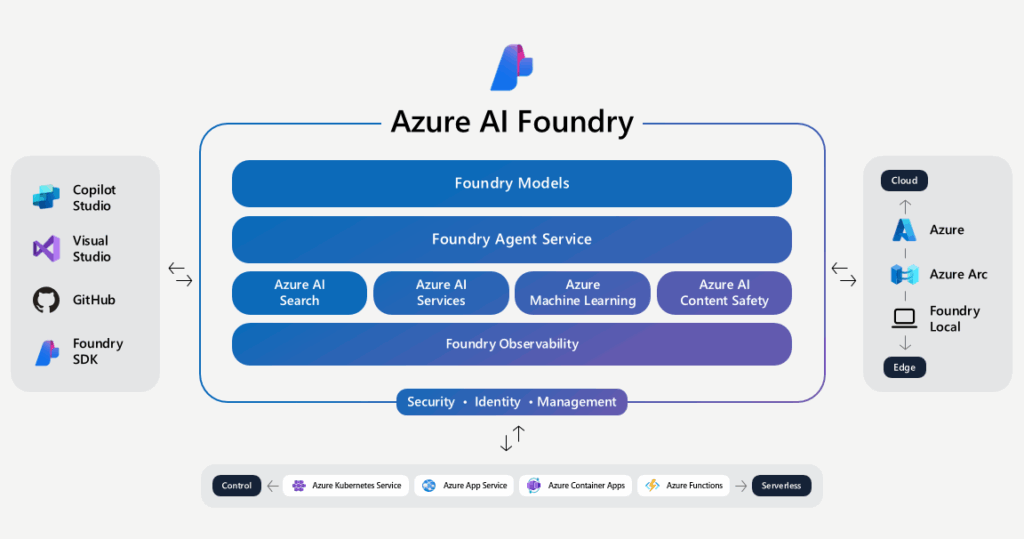
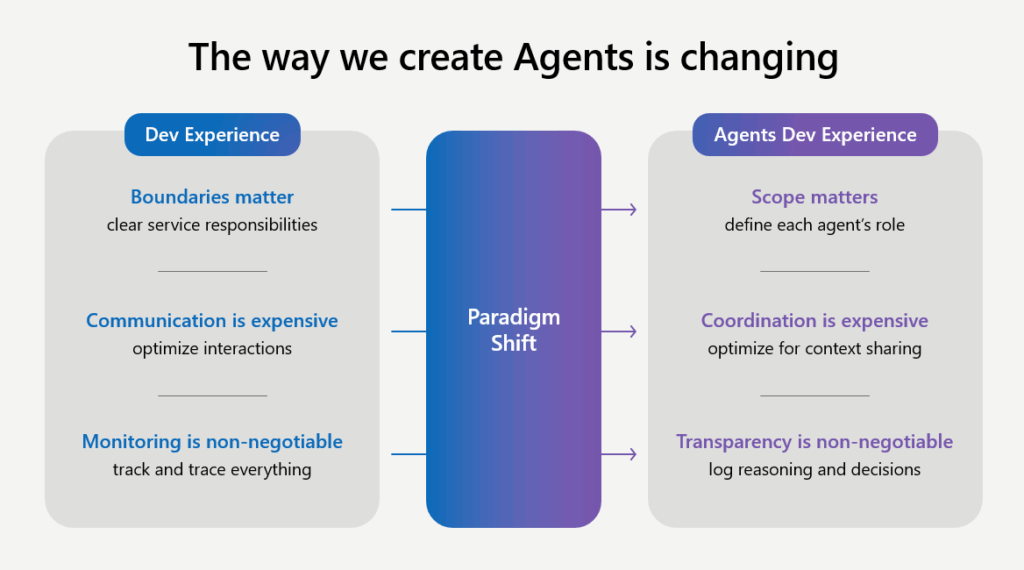
Azure AI Foundry was introduced in the session “Building enterprise-ready AI Agents with Azure AI Foundry” as a powerful service for customizing, orchestrating, and deploying AI agents. It supports interoperability across frameworks and tools, including non-Azure agents via the Agent protocol. Various agent patterns were discussed, such as Sequential, Concurrent, Handoff, Group Chat, Magnetic, and Workflow, offering flexible design options for enterprise applications. I could see us using this offering as well as Agent Bricks in the future to avoid vendor lock-in and evaluate each service head-to-head. The session ended with a comparison of modern application development and intelligent application development as well as the paradigm shifts that are happening throughout.
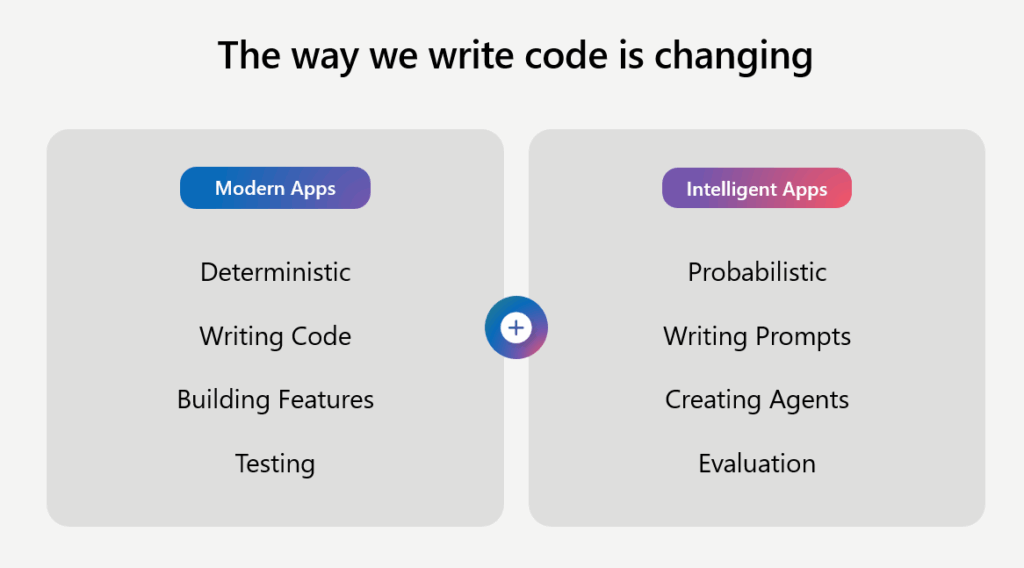
Modern applications are deterministic, you write code, you build features, and you test. While Intelligent applications are probabilistic, you write prompts, you create agents, and you evaluate. Where the paradigms of boundaries become scope, communication is less important than coordination, and monitoring becomes transparency. In other words, agents no longer have a clear scope of responsibility, but rather a role in a team; where communication used to be the expensive part of maintaining LLMs, but now the handoff of context between agent systems is key to reducing cost, and finally how the past emphasis on tracking outputs has now become log reasoning and the decisions made from them.
The last session I attended was “Agentic use of GitHub Copilot within Visual Studio” where GitHub Copilot’s integration with Visual Studio was explored in depth. The session was insightful in terms of how much can be accomplished with the two tools. Like when project context is stored in GitHub, agents can understand high-level goals and execute tasks like unit testing autonomously or write code for you! Even without full context, Copilot can accelerate onboarding and development by leveraging technical documentation and design wikis to explain code. Apparently, we are already using this where I work, but I would like to see what benefits we can see by switching from Azure DevOps/Jira to GitHub when it comes to data engineering with PySpark and not just writing applications.
The tour concluded with a call to action: while a strong foundation for agentic systems is being laid, organizations must move quickly to keep pace with change. Clear messaging around AI, rapid evaluation of business value, and secure knowledge sources are essential. The technologies which were showcased are poised to revolutionize how agentic systems will interact with enterprise data and beyond.
I’ll be attending a similar event in Toronto at the end of the month which will be hosted by Databricks. I’m curious to see what similarities in offerings they present and how the plan to position themselves in the AI agent race against vendors as big as Microsoft.