
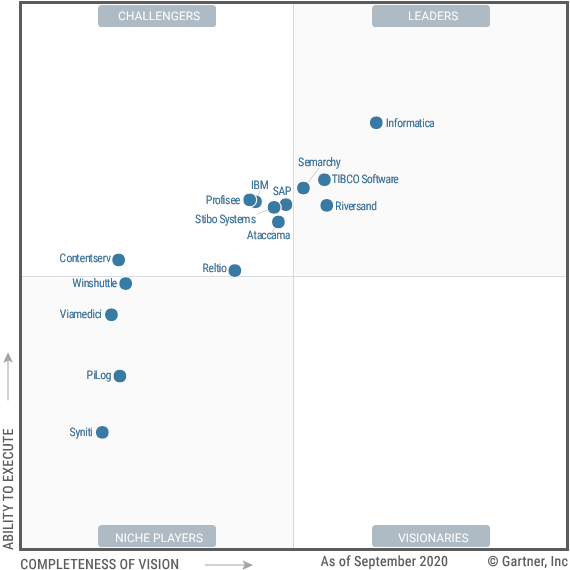
When I first relocated to Colorado I worked for a global company in a local role. During my almost 5 year stay there, I grew into a global role with oversight over all things data coming from and going into their ERP system. I helped with 6 regional implementations into a global JD Edwards system and worked very closely with the brilliant Jiri Svoboda. At the time he held the position of Global Master Data Manager and I head the position of Global ERP Data Architect Manager. We were at the beginning of the company’s digital transformation and were tasked to take the somewhat manual Data Migration and Master Data Management (MDM) processes and modernize them. We shopped around various Gartner leaders in data management solutions. We had demos and POCs from both IBM, Informatica, and some boutique data management vendors. We landed on Informatica because they were, and still are, lightyears ahead of others in the world of MDM. What we learned was that Master Data Management, Data Governance, and analytics on data quality are super important, but tools will only get you so far. In this blog post, I’ll share my perspective on what worked for us and what I would do differently if I had to do it again.
Taking antiquated ERP systems and getting all of their data, not just master data, into a global ERP system is no easy task. Without things like MDM, you could create a nightmare of bad/duplicate data. I chose to build a robust framework that could take any source input and through rules defined in Informatica Analyst, would be able to transform and harmonize these data to master records in the target ERP system. We used things such as fuzzy matching to identify potential duplicated master data and worked to clean the offenders in the source system. We learned from previous migrations using RPG programs and Excel, that MDM and DQ are probably the most important factors in a successful ERP implementation.
This takes me to my first point in MDM; Data Quality (DQ). There are two ways to manage Data Quality; Passive and Active Governance. With Passive Governance, you create things such as the fuzzy matching algorithm I just mentioned, and create reactionary reports/dashboards based on them. With Active Governance, you get ahead of things by controlling Master Data in a central repository or through processes that ensure data quality before the master record is created in any system. When we first started our endeavor into modernizing ERP implementations, we had only Excel at our disposal. We would do things such as matches on natural keys or descriptions to identify potentially duplicated data. We put in our roadmap to build Informatica Data Quality (IDQ) pipelines to first tackle these data in a passive manner, but to eventually move them into an active state and use the same rules to check quality before the master data was created in a target system.
IDQ was a great tool for defining these types of quality pipelines. Even though we never implemented one, we learned so much from the capabilities of the tool we were able to build them into our antiquated quality checks in Excel or SQL. Some example of these would be:
- Performing data profiling to learn about types and cardinality
- Create quality checks like:
- Natural Keys follow a correct pattern like (###) ###-#### for a phone number
- Country Codes follow the ISO standard for a 2 or 3 character code
- Full name fields are last comma first
- Addresses actually exist with valid cities and states
- Create reports based on quality checks
What we implemented was a Registry style of MDM. We had various checkpoints along the journey of new data incoming to our ERP system which would use rules like the one above to flag potentially bad data after it was created during test migrations to the target. A Registry style MDM is one of a few different architectures you can take when implementing MDM. With it you take a passive approach to MDM and use it as a tool to identify duplicate or incomplete data in your systems.
The other commonly used architectures for MDM are Consolidation, Coexistence, and Transaction styles. In some sense a data warehouse is a Consolidation style MDM, but the rules are built into the Extract, Transform, Load (ETL) process. There is no manual intervention for cleansing or managing data to create what is known as a Golden Record. Although a Data Warehouse contains a Golden Record, it is often created using ETL logic and not an MDM tool. In the Coexistence and Transaction architectures of MDM, golden records are maintained in a centralized MDM and written back to source systems. This is often the dream state of any MDM, but proves very hard to implement, but with saying that, I’ll get into a little more detail of what each architecture looks like.
Registry Architecture:
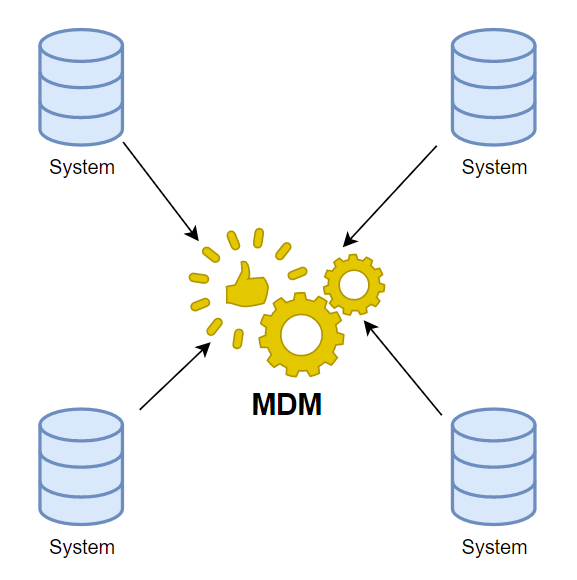
A Registry MDM architecture is purely informational. Master data is collected from various source systems and matched through different algorithms in an MDM tool. This information is then used to update the source systems and create a harmonious version of each record. This works great if your data is spread out all over the place and governance might be hard to accomplish. It is the easiest of the MDM architectures to establish and maintain.
Consolidation Architecture:
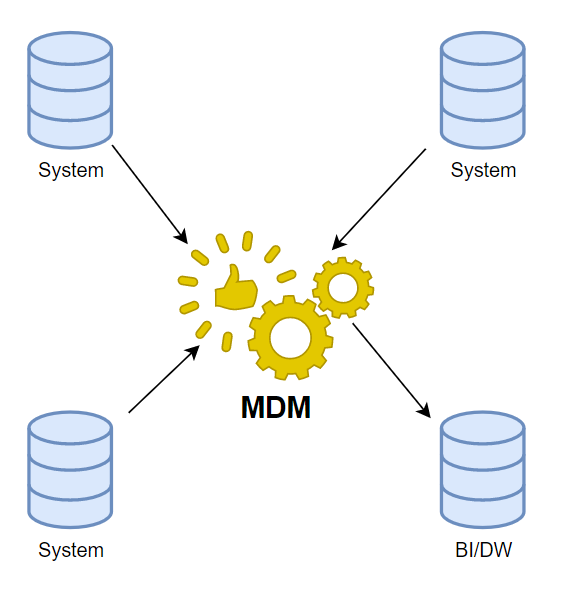
A Consolidation MDM architecture builds on the Registry style, but maintains its own version of a Golden Record. You can think of this approach as gathering information from all sources and using it to create a single master record for reporting or analytics. Like I stated previously, ETLs in Data Warehouses attempt to automate this process, but without human intervention, duplicate or incomplete data can easily slip through the cracks. This approach is a great approach for creating an easily reported on version of master data and just a little more complicated to implement than the Registry style.
Coexistence Architecture:
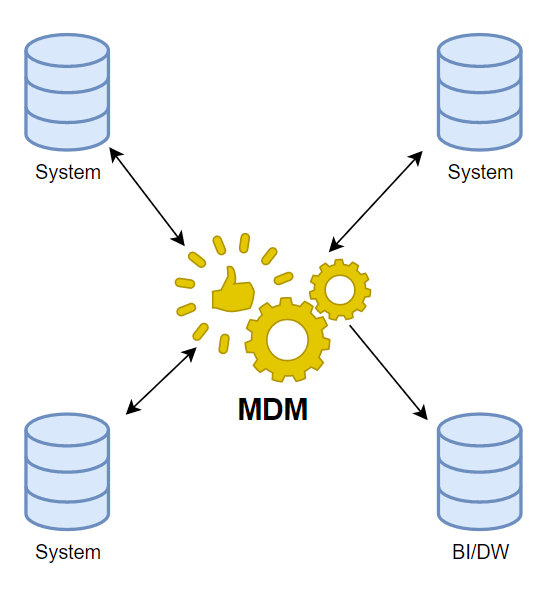
With a Coexistence MDM architecture, the MDM tool is used to broker the exchange of master data between all systems. Master Data can be created within the MDM tool or in the source system as well as updated in the MDM tool or the source system. The MDM tool is used to maintain the Golden Record and that is then synced with all systems that subscribe to the MDM tool. The benefit of this approach means that there is one Golden Record that is consistent across all systems. This to me seems incredibly hard to achieve because of differing data architectures across all systems as well as all the parties involved in managing the data itself.
Transaction Architecture:
In the Transaction MDM architecture, the MDM tool becomes the system of record. You can create any type of Active DQ here to enforce quality checks before data is created in any system. This approach was the goal of Jiri and mine, but it was never attained because we both quit our jobs due to burnout and very very poor management. I dreamt of the day we could have used an MDM tool to create and manage all master data.
No matter what approach you take on your Data Quality or Master Data Management journey, everything boils down to one thing: People. No matter how much technology you throw at your data, there will also be the human element to it. Data has domains and people own those domains. Without people you cannot establish the rules for Data Quality or how to manage the data. Without people there is no way to action upon any of the reactionary DQ approaches. Without people there is no way to clean up bad data whether it be in a MDM tool or in the source system.
This has always been a struggle, not only with DQ or MDM, but with all things data. When dealing with Machine Learning POCs, you often find that incomplete or bad data is what stands between you and a usable model. Getting people to own their data and maintain its quality is often a losing battle when it is attempted with a bottom up approach. It’s in my opinion that these initiatives need to come from top down. There needs to be Master Data Managers, Domain Owners/Product Owners, and Data Stewards for any of this to work. Without this kind of formal directive most MDM journeys are doomed to fail.
If I had to take on the challenge of migrating quality data into an ERP system again, I probably wouldn’t take the challenge because ERP implementation are hell, but since I’ve lived through so many I’ve walked away with a ton of valuable knowledge that goes beyond ERPs. For that I am grateful and try my hardest to make what I’ve learned along the way into good practices in whatever role I am engaged in at the time.
What about you? What’s your approach on MDM or DQ? What challenges have you faced in trying to maintain clean data?