
There are many approaches to NRT and some might argue that there really isn’t a reporting need that warrants the ingestion of data at this rate. Sure, if there’s streaming available and you want to see what’s going on at the current moment, then a Lambda architecture might be what you are after. But what about those other use cases when a user just wants to see their data in a dimensional model as fast as possible? I typically argue against why that’s even necessary, but sometimes the powers at be dictate it to happen. So what approach do you take?
The following video highlights some of the approaches you could consider.
It’s basically a footnote in this video since Delta Lake was just being mentioned at this point in time, so I wanted to pick up where the video left off and explore the method I’ve used to get data near real time into a dimensional model using the Databricks Data Lakehouse architecture.
The goals for this project are as follows:
- Have data into a dimensional model within 3 minutes from an OLTP system
- Utilize the Medallion Architecture (3 Containers in ADLS)
- Handle schema evolution
- Keep a historic record of each batch in an immutable bronze zone
- Enable a rebuild of a type 2 dimension from the bronze zone if needed
Since our data lake is structured with raw incremental parquet files in our first zone and delta tables in our second and third zone, we decided it would be best to take the following approach:
- Read Change Tracking entries for each source table since the last version we pulled directly into Silver zone delta tables.
- Run any transformations needed on with tables to update our dimensional model in the Gold zone.
- A completely separate process for archiving treats the Silver zone as any other OLTP source and pull records based on date from it to the Bronze zone at the granularity we foresee needing in for Type 2 dimensions (Daily).
I’m not going to get into super detail on our logging and auditing process, so I’ve set up a super watered down version of a couple tables we use to keep track of high watermarks. A high watermark is where you read the data from a table up to the last time you processed it. We handle a variety of high watermarks, but in this sample I’ve boiled it down to the two most common: Change Tracking and Timestamp. The processes for pulling increments from a source table is as old as time, so I won’t bore you in those details either. Just know that we keep track of those values each time we load a table to delta as well as when we pull from delta to our bronze zone. In addition to watermarks, we keep all our sensitive information about servers and their logins in a key vault and only keep the secret names in these configuration tables. But for the sake of simplicity, I’ve hardcoded many of these in the sample.
Below is a flow chart of how we use the metadata to drive the collection of new records.
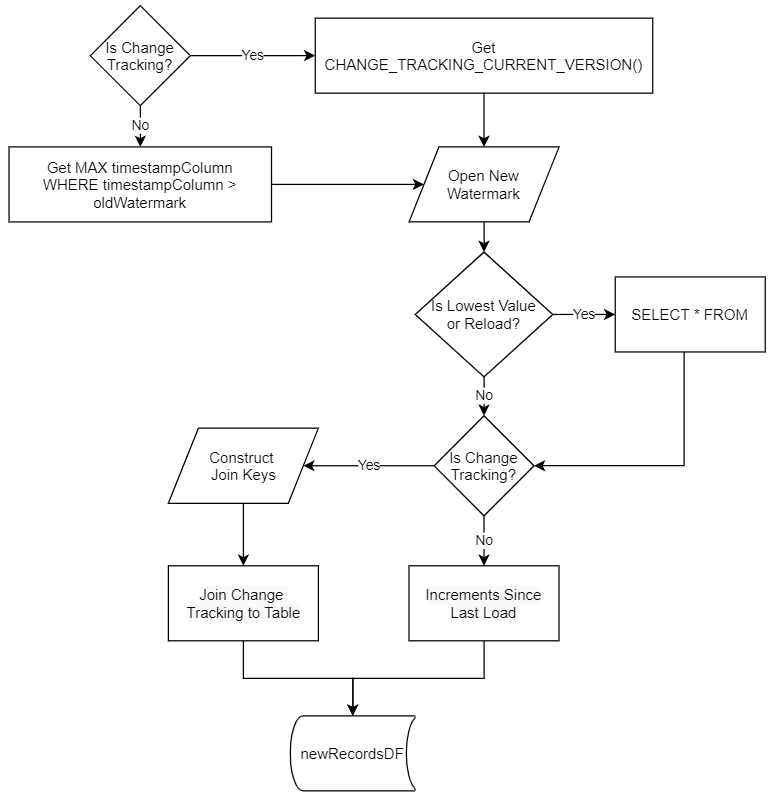
Once we have create a dataframe based off of a high watermark query we can determine whether to write that dataframe directly to the delta format or to merge the records into an existing delta table.
silverPath = f"{silverMnt}/{databaseName}.{tableName}"
dbSql = f"CREATE DATABASE IF NOT EXISTS {databaseName}"
#create the database if it doesn't exist - this will keep things organized in the future
spark.sql(dbSql)
if (toEntityName.lower().split("."))[1] not in [t.name for t in spark.catalog.listTables((toEntityName.split("."))[0])]:
#if there hasn't been a processing of a silver entity then we have to create the delta table from scratch
newRecordsDF.write.format("delta").mode('overwrite').save(silverPath)
#create the delta table from the delta folder if it hasn't been created already
deltaSql = f"CREATE TABLE IF NOT EXISTS {toEntityName} USING DELTA LOCATION '{silverPath}'"
spark.sql(deltaSql)
else:
print("Updating Delta Table")
#merge the new records into the delta table
deltaTable = delta.DeltaTable.forPath(spark, silverPath)
joinConditions = ""
for col in primaryKeys.split(","):
joinConditions = joinConditions + "source." + col + " = target." + col + " AND "
joinConditions = joinConditions[:-5]
deltaTable.alias("target").merge(
newRecordsDF.alias("source"),joinConditions
).whenMatchedUpdateAll().whenNotMatchedInsertAll().execute()
As you can see in the above code, we check for the existence of the database we are writing to and create it if it’s not already created. Then we proceed to check the Spark catalog for the delta table’s existence as well. If it does not exist, we write the entire dataframe to the silver zone and then create the table using the path to the files in ADLS. If it already exists, we merge using the join columns from the metadata and upsert all target columns. By selecting all columns in the newRecordsDF queries and merging in this manner, we can handle schema evolution quite easily.
Let’s walk through the database setup and an example run.
We first load our test source tables with data.
INSERT INTO [dbo].[dbrDemoTransactions]
([TransactionName]
,[TransactionAmount])
SELECT [TransactionName], [TransactionAmount]
FROM (
VALUES
('Test Tran 1', 420.69),
('Test Tran 2', 694.20)
) AS t ([TransactionName], [TransactionAmount])
GO
INSERT INTO [dbo].[dbrDemoTransactionsDt]
([TransactionName]
,[TransactionAmount])
SELECT [TransactionName], [TransactionAmount]
FROM (
VALUES
('Test Tran 1', 420.69),
('Test Tran 2', 694.20)
) AS t ([TransactionName], [TransactionAmount])
GOIn the seed data sample above we are loading into two tables, one tracked by change tracking and the other by date. They both have the same schemas and have the following metadata describing them:

After running them through the notebook for an initial load we can see that both tables are loaded correctly.
We can then proceed to run another set of queries to demonstrate newly added data and the incremental loading process.
INSERT INTO [dbo].[dbrDemoTransactions]
([TransactionName]
,[TransactionAmount])
SELECT [TransactionName], [TransactionAmount]
FROM (
VALUES
('Test Tran 3', 123.45),
('Test Tran 4', 456.78)
) AS t ([TransactionName], [TransactionAmount])
GO
INSERT INTO [dbo].[dbrDemoTransactionsDt]
([TransactionName]
,[TransactionAmount])
SELECT [TransactionName], [TransactionAmount]
FROM (
VALUES
('Test Tran 3', 123.45),
('Test Tran 4', 456.78)
) AS t ([TransactionName], [TransactionAmount])
GOAs you can see the watermarks have been updated and we will use them to pull just the new changes:

And the new changes in the delta tables:
And now we see that both tables have updated successfully to what we’d expect to see.
The same framework can be used to point at delta tables and treat the SyncDateTime column as a watermark to incrementally load End of Day batches to the bronze zone. This allows you to future proof your solution to create Type 2 dimensions if needed in the future.
There are other notebooks in our framework which handle the using of the silver zone delta tables to create a dimensional model in both our gold zone and Azure SQL as well as patterns for handling things like deletes and full reloads. I might blog about those in the future, but for now this shows the basics of how we accomplish NRT with delta.
The complete code for both the databases and the notebook can be found here: https://github.com/CharlesRinaldini/NRTWithDeltaLake