





I feel as if the end of the year is always conference season for me because my summers are usually jam packed with travel since that is the only time of year my wife has off. I missed the Databricks conference in San Francisco this year because of that, but made up for it in the last quarter by attending various other events and even a two day “Databricks World Tour” event in New York City.
When I first moved to Colorado more than a decade ago it was because the job market for database jobs was basically nonexistent in South Texas if you didn’t live in Austin. I wanted to start a career after working in government contracting for a little after college and wanted to be in a place with a lot of options. Naturally, Denver was one of these places. One way to open some doors to job opportunities was to join a user group, and since up until that point in my career I had only worked with SSIS and SQL 2008 R2, the Denver SQL User Group was the obvious choice. Funny thing is, I never attended a user group meeting until 2018. I was always a member and kept up with the topics being discussed, but never actually got around to going. This is because my first job in Denver was with a group of seasoned ERP and EDI developers who used the Microsoft BI platform as just a utility to support other efforts and their main focus wasn’t around any new developments with the tool or other cloud offerings.
It wasn’t until I got a job with a somewhat “startup like” organization that I was exposed to people who actually attend the user group and went to SQL PASS; and that’s how I found myself at my first PASS Summit in 2018. Since then, I’ve become more active in the user group as well have attended more PASS Summits and other conferences. This year alone, I’ve gone to numerous user group meetings, DAMA meetups, Denver Startup Week, SQL Saturday, Denver Dev Day, Databricks World Tour NYC, and PASS Summit.
I’d like to take this blog post to share what highlights I’ve learned during some of these as well as some plans I might have to implement them.
First of all this year mentioned at SQL UG meeting, SQL Saturday, and heavily during PASS was the coming and GA of Fabric; which is the consolidation of various Microsoft data and analytic tools under one product family with additional features. I’m sure everyone knows about this, but from speaking to others, still don’t know how it might fit into their current data practices; myself included. From some of our internal testings, it would make sense for ourselves, as well as many others, to first implement Fabric using shortcuts. But it would appear that doing so doesn’t offer you as much performance as if you landed your external data directly into the OneLake, so this might not be the best approach. Well what if you decide to use OneLake exclusively and move a bit of your transformation or ingestion into Fabric using pipelines or notebooks? Right now the pricing model is based on capacities. They are allocated to tenants and can be shared amongst workspaces:
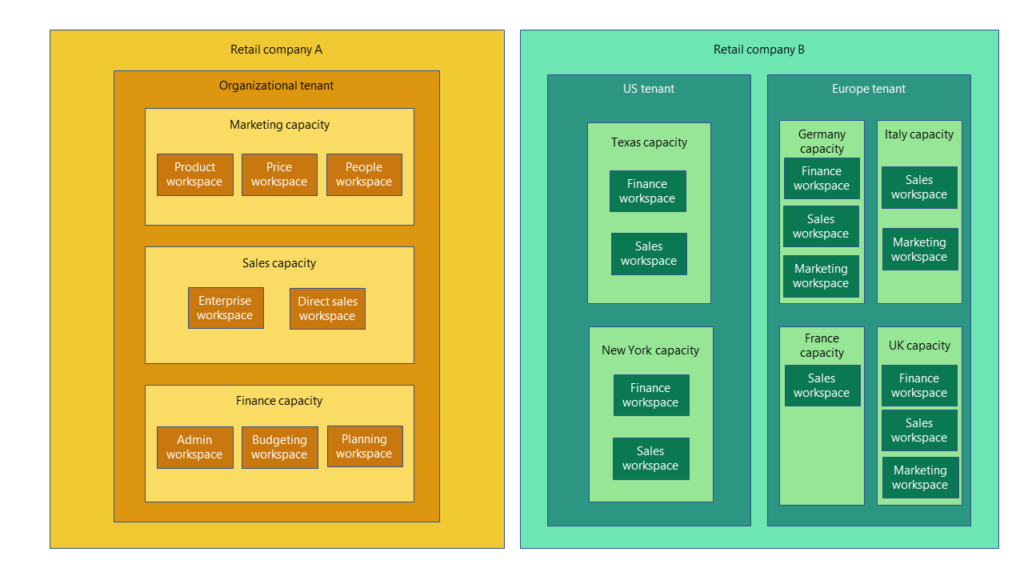
This is much like an All Purpose Compute in the Databricks world. Which brings me to my point of what might be problematic. In the Databricks world the only reason for All Purpose Compute is for adhoc sql, data exploration, and development. You would almost never run your workloads on those because a huge job or poorly written sql could bring the environment to its knees. Also the cost associated with a huge workload makes no sense to run in anything other than Jobs Compute or Cluster Pools. There currently is not similar offering in Fabric. That alone makes me not want to move any transformation workloads over to it. Fabric to me is really an alternative to SQL Warehouses in Databricks or a replacement to Azure Synapse Serverless since the compute will be ran on Spark instead of SQL DW. So the jury is still out on that one and I will have to write an update in the future if things change or we find a different way to adopt Fabric.
The next set of big developments revolve around Databricks. I really wish I was able to attend the Databricks conference in San Francisco earlier this year, but the two day conference in New York had to suffice. It’s a shame because the focus of the “World Tour” events was that or “Generation AI”. Which meant a very heavy focus on generative AI. Don’t get me wrong, this is the future, but I would have loved to also attend some sessions on Spark optimization or what’s next on the Databricks roadmap. Regardless, it was still a valuable experience. I would say after attending this conference as well as PASS, I see some potential for generative models in my day to day. The Databricks copilot for instance might be a good utility for generating boiler plate code, or the Azure Data Studio copilot would seem very helpful for generating the beginning of procedures if not entire procedure themselves. I actually plan to try both out in a future blog post.

In relation to PASS Summit, some of the other big announcements that were made we GA announcement of preview features announced earlier in the year. One that stuck out to me was that of the pricing model for SQL Managed Instances. The start of 2TB of storage before having to go up to 16 vCores has now dropped to 8 vCore, which is great if you require more storage and don’t really need the additional compute. Also, two big announcements that effect me are first, configurable tempdb sizing and transaction log throughput doubling. This is because many of the workloads that are utilized daily at my current job are crippled by both of these. I’m hoping in the weeks to come we can start to tune them based on these two features. Lastly, the feature I’m very excited for is the Create External Table As Select or CETAS. We had a contractor hypothesize earlier this year about how this feature might be able to work with Databricks auto loader but never tried it. After looking into it future, and taking into consideration the GA of calling external REST endpoints from Azure SQL, it might be something to write a blog on.
It will be exciting to see what comes of these developments in the future months. I will definitely reflect on all the learnings I’ve had in the past few weeks and hopefully have some new material to blog about soon.