
Background
There’s not much out there on the subject of how to unit test Databricks notebooks when it comes to using them to create a Kimball data warehouse or a data lake house. This is because of a couple reasons. One: most people who have historically worked in Business Intelligence aren’t in the habit of writing automated unit testing for their code, or two: unit testing of notebooks seems to be an impossible task to accomplish if you keep your ETL code entirely inside of Databricks notebooks. Some might argue that notebooks aren’t enterprise grade ETL in terms of SDLC and CI/CD capabilities. I agree. If you’ve got a team of software developers who are well versed in OOP then you should be building Python wheels that are deployed and ran on your Databricks clusters. But what happens when you’ve got a team who is only familiar with tools such as SSIS or Informatica, and the extent of their development experience begins and ends with the Script Component and Script Task in SSIS?
We don’t want to create a solution that can only be maintained by people with computer science degrees or extensive programming experience. We want to build flexible frameworks that suit the team who is supporting them. My goal in this post is to show how we worked around the problem of keeping development of ETL familiar using SparkSQL and notebooks, but also built a framework outside of Databricks that could unit test our notebooks, e.g. the notebook is considered a unit.
Overview
The goal was simple, move an on-premise data warehouse solution to the cloud, but use the modern data warehouse architecture instead of doing a lift-and-shift. What we chose to implement was a Data Lakehouse using the Databricks Medallion Architecture and the new offerings from Azure Databricks in terms of their distribution of Delta Lake.
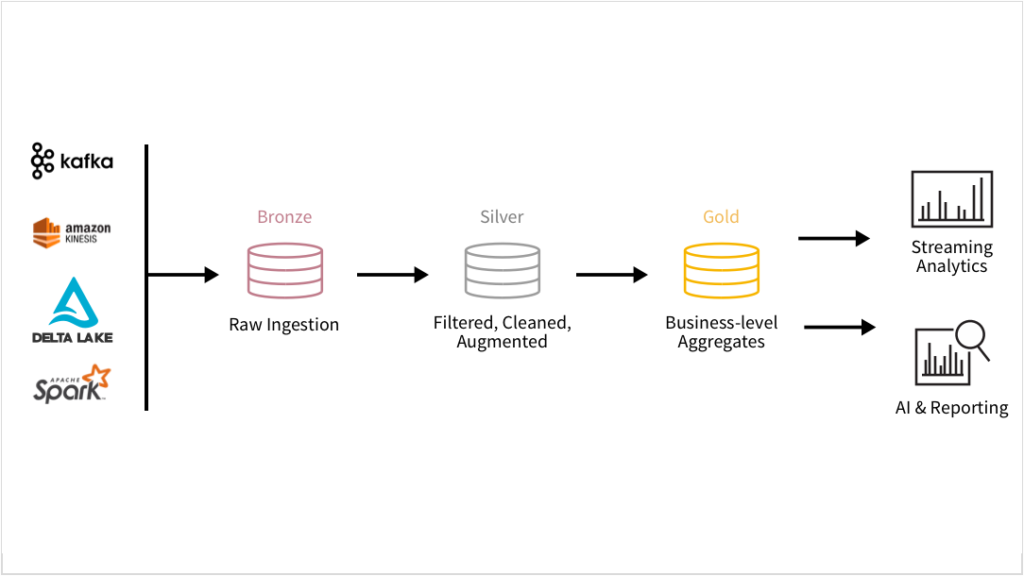
We’d move the ingestion of our data from costly SQL Server ODS’s to ADLS Gen2, then further transform and use the data within the data lake. We’d then replicate whatever we needed from the Silver and Gold zones to an Azure SQL Database to then plug into our existing SSRS server as a data source. This implementation was chosen to be future fitting as we planned to leverage Databricks SQL Analytics in the near future. We’d use ADF for ingestion where we saw fit and then handle everything else with Databricks – especially the transformations. We wanted the Azure SQL Database to act only as a serving layer that would run stored procedures on a dimensional model to generate report data.
The Problem
The problem as stated before, is how does a team of BI developers who are used to working in SSDT efficiently work in Databricks? We knew we wanted to replace each stored procedure with a notebook and we knew we wanted some method for testing these.
There’s a great write up here that explains the best approach for doing this, but if you’re in a position like the one I found myself in and want to take a hybrid approach, then read on.
The Solution
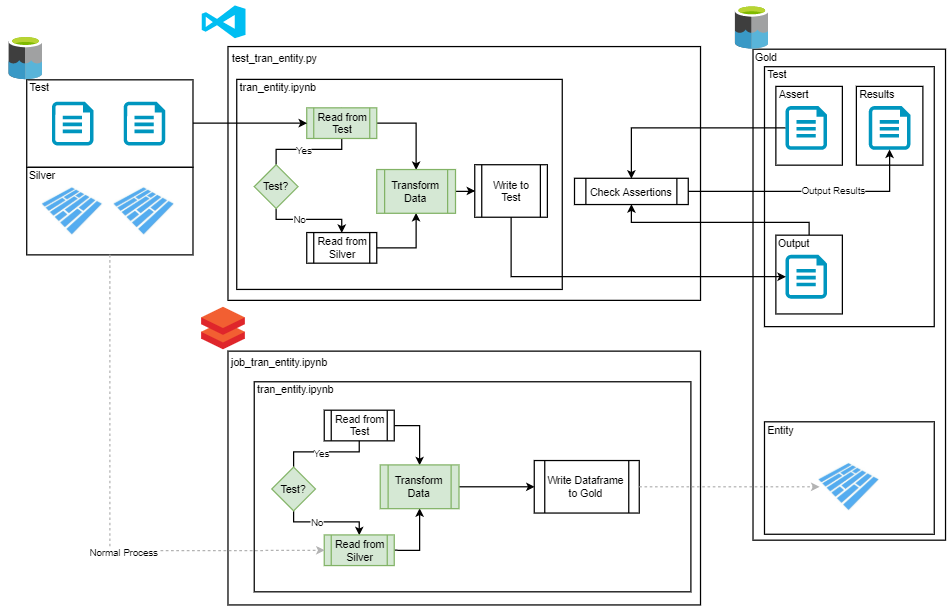
As seen above, the proposed solution was to create notebooks in a way that could source data from different locations depending on how they were called. If called in a test configuration they would source data from a Test zone in the data lake, but if called from any other configuration they would source their data from our Silver zone delta tables.
The only challenge we faced was how do we orchestrate this to easily fit within a CI/CD pipeline in Azure DevOps.