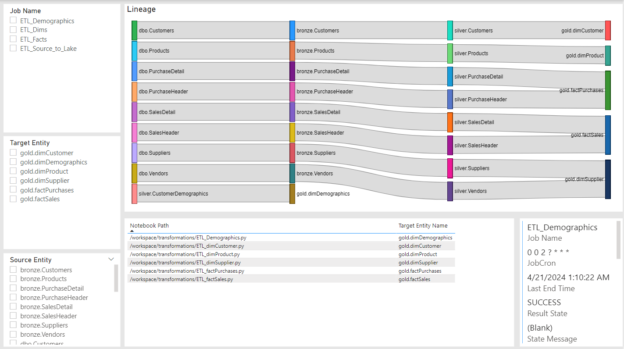
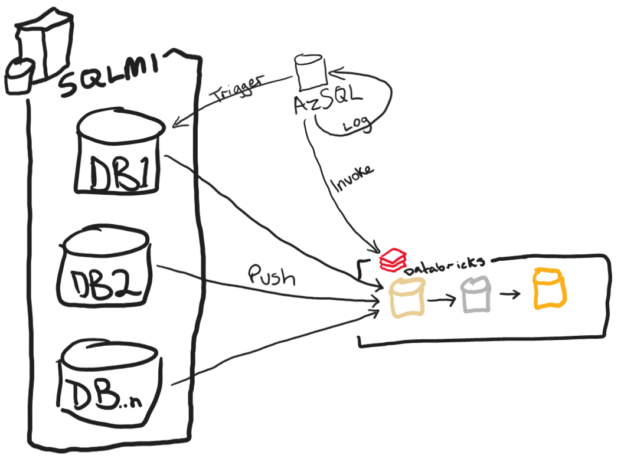
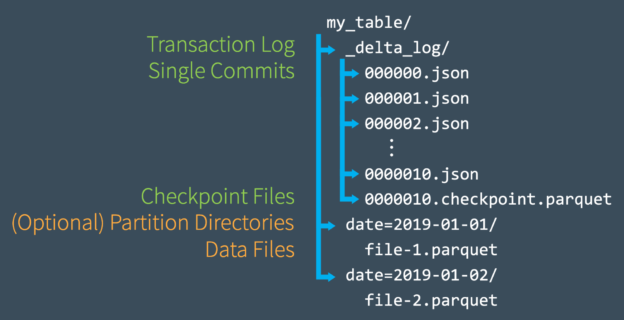
I saw a Reddit thread last week about someone’s issue with having to serve Delta table data at very low latency. This is typical of OLTP applications. Sometimes data that is stored in your lake needs to be copied to a RDBMS to provide the speed that is needed in mobile or desktop applications. This is a common problem I have faced in the past years where before things like lakehouse applications, there was no real easy way to accomplish the speed that was needed. Often, we found ourselves copying small sets of data and merging them into target tables, but other times we needed to copy huge sets of data.
Continue reading
Fast-ish Load Data to SQL from Databricks
Leave a reply